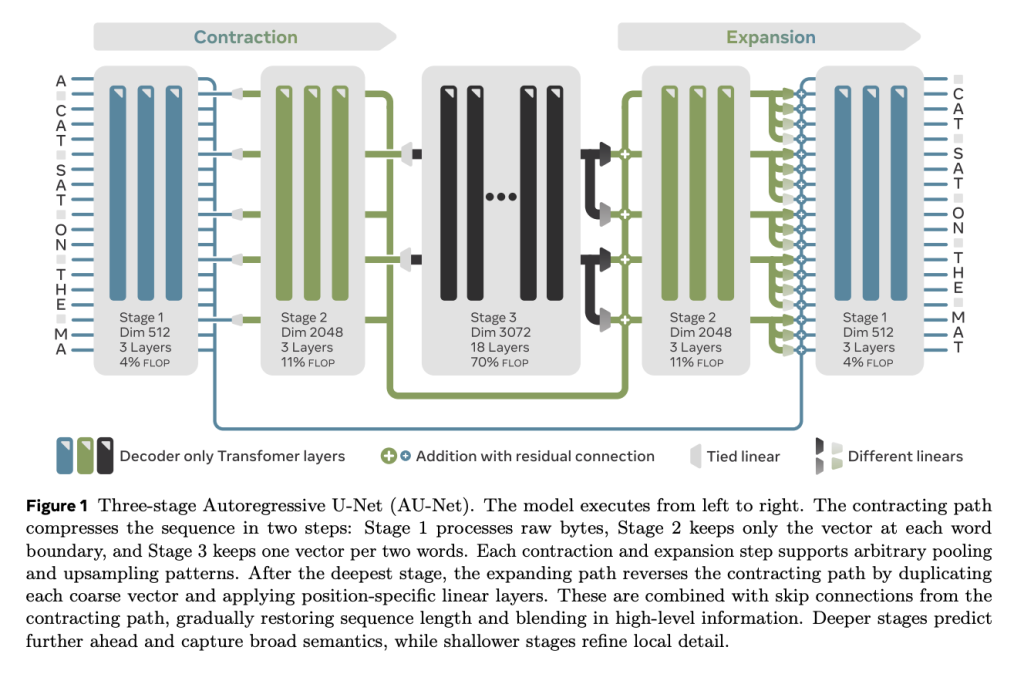
Language modeling plays a foundational role in natural language processing, enabling machines to predict and generate text that resembles human language. These models have evolved significantly, beginning with statistical methods and progressing through neural architectures to today’s large-scale transformer-based systems. At the center of many applications, such as chatbots, translation tools, and text completion engines, language models interpret and generate sequences of words or bytes. Their effectiveness largely depends on the underlying architecture and the data representations used. As the demand for more efficient and scalable models grows, researchers continue to explore new structures and training methods to improve performance, handle longer contexts, and reduce computational load. Among these efforts, combining ideas from convolutional architectures with autoregressive prediction has emerged as an intriguing approach. Challenges with Tokenization and Transformer-Based Language Models One of the main issues with language modeling is the excessive use of token-based models and transformer models, which are computationally expensive and generally inefficient for processing at the byte level or even across languages. Techniques such as Byte Pair Encoding control sequence lengths but create inconsistencies between languages and domains. Transformers, although precise, lack scalability due to their quadratic complexity. Although competing approaches, such as sparse attention, attempt to solve this issue, they typically do so at the expense of simplicity or performance. Byte-level modeling with flat transformers has demonstrated only partial success, underscoring the need for new architectures that can process raw byte inputs without tokenization while achieving excellent performance. Introducing AU-Net: A Token-Free Byte-Level Language Model Researchers from FAIR at Meta, TAU, INRIA, and LISN, CNRS & Université Paris-Saclay, INSA Rouen Normandy, LITIS, Rouen, France, introduced a new Autoregressive U-Net (AU-Net). This model integrates the ideas of convolutional U-Net designs with autoregressive decoding processes. In contrast to transformer systems, AU-Net does not require tokenization and works directly on bytes. The architecture is designed to enable parallel and efficient generation, with the autonomy to incorporate autoregressive capabilities. It achieves this by hierarchically encoding down-sampled convolutions and then up-sampling stages, which restore the original sequence size. Notably, AU-Net presents a splitting mechanism that enables predictions to be performed over subsegments of the sequence, enhancing scalability. This design shift also ensures that the model’s complexity increases linearly with sequence length, rather than quadratically. The researchers deployed this model across several language modeling benchmarks and multilingual tasks to test its effectiveness in both low-resource and large-scale settings. AU-Net Architecture: Multi-Scale Encoding and Parallel Inference The AU-Net architecture is implemented with multiple scale stages that reduce and then reconstruct input sequences using convolutions with strides. During training, each segment of the input sequence is predicted in a masked fashion to maintain the autoregressive property. The model uses a learned splitting function to divide input sequences into non-overlapping groups, which are then predicted concurrently and combined into a full output. It supports both shallow and deep configurations, with models ranging from 3% to 75% of the training compute budget compared to standard baselines. For example, one configuration trained on 200B tokens with 8 billion parameters achieved highly competitive results. Another version, trained on 60 billion tokens with a one billion-parameter model, achieved a 35.7 BLEU score on standard translation tasks, outperforming baseline models trained on the same data. Additionally, AU-Net demonstrated faster generation speeds due to its parallel decoding, offering a significant benefit for latency-sensitive applications. Benchmark Results Show Competitive Edge Over Transformers The experimental results showed strong performance across a wide range of tasks. On Enwik8, a byte-level compression benchmark, AU-Net achieved 1.01 bits per byte, surpassing a transformer baseline that reached only 1.02 bits per byte. On PG-19, a long-context language modeling task, the model achieved 2.61 bits per byte compared to 2.75 from standard transformers. AU-Net also scaled effectively across compute budgets, achieving 43.3 BLEU on FLORES-200 translation with an 8B model size trained on 200B tokens. In multilingual evaluation using FLORES-200, the model outperformed token-based transformers across low-resource language pairs. It also demonstrated better cross-lingual generalization within language families, achieving a BLEU score of up to 33.0 in several configurations. When evaluated under equal compute and data budgets, AU-Net either matched or outperformed transformers, with generation speeds improving by 20% to 30% in certain settings. Key Contributions and Performance Insights from AU-Net AU-Net eliminates the need for tokenization by operating directly on raw byte inputs. On Enwik8, AU-Net scored 1.01 bpb, surpassing transformer baselines with 1.02 bpb. On PG-19, it achieved 2.61 bpb, improving over the 2.75 bpb of standard transformers. FLORES-200 multilingual evaluation showed up to 33.0 BLEU, outperforming token-based systems. Byte-level models trained with AU-Net maintained high performance across high-resource and low-resource settings. Generation speed improved by 20%–30 %, supporting fast, parallel inference. Scaling laws held; performance improved with increased model size and data. The model showed better cross-lingual generalization and robustness to noise. Efficient use of compute; AU-Net matched or exceeded transformer performance at lower compute budgets. AU-Net is a viable alternative for large-scale language modeling tasks, including multilingual and byte-level applications. Conclusion: AU-Net’s Practical Benefits and Scalability Potential In conclusion, the researchers provided detailed scaling analyses showing that AU-Net adheres to predictable hyperparameter scaling laws. It benefits from increased model size and training tokens in a manner consistent with the practices observed in transformer models. For example, under compute-matched training settings, AU-Net’s performance improved steadily with increased data-to-model ratio, matching the gains seen in transformer counterparts. Importantly, AU-Net was able to scale up to models with 8 billion parameters, demonstrating effective training and showing that the architecture is capable of supporting high-capacity systems. In extended evaluations, the model maintained its efficiency when applied to downstream tasks, showing strong performance in language generation, translation, and byte-level prediction benchmarks. AU-Net also proved to be easier to train and more robust under noisy input conditions compared to token-based models. Why This Research Matters? This research matters because it challenges the long-standing reliance on token-based language models by introducing AU-Net, a byte-level autoregressive architecture that eliminates tokenization overhead while achieving competitive or superior performance. By processing raw